https://www.youtube.com/watch?v=zjkBMFhNj_g
Training
Pre-training: Using next-token prediction as a lossy compression of a large chunk of internet. Quantity over quality.
Fine-tuning: Same thing as pre-training but you swap out the internet documents for hand-made documents by people who create queries and answers and feed that in. Being trained on these changes the formatting and style of the response to be more like a helpful assistant. Quality over quantity.
More concretely:
Stage 1: Pretraining → every ~year
- Download ~10TB of text
- Get a cluster of ~6000 GPUs
- Compress the text into a neural network, pay ~2M, wait ~12 days
- Obtain base model
Stage 2: Finetuning → every ~week
- Write labeling instructions
- Use people to make 100k high quality ideal Q&A responses and/or comparisons (compare on multiple responses instead of generating your own response)
- Finetune base model on this data, wait ~1 day
- Obtain assistant model
- Run a lot of evaluations
- Deploy
- Monitor, collect misbehaviors, go to step 1
The unhelpful hallucinations don’t get fixed with finetuning. The finetuning just kind of directs the dreams into generally more helpful ones.
Scaling Laws
Performance is a remarkable smooth function based on
- Number of parameters
- Amount of text trained on
Tool Use
Plugged in models can recognize when to use other tools to do things instead of just using next-token prediction. Example: using a calculator when recognizing that it needs to add two big numbers, writing code to create data charts.
Future Directions
System 1 vs. System 2
Right now, LLMs only have System 1s. They aren’t capable of rational, multi-step thought, where they hold and manipulate a tree of possibilities or criticize and question outputs. From me: Next-token prediction is literally the definition of System 1 (that’s probably why it’s so good at conversing and small-task programming → very fundamentally System 1 things).
Self-improvement
AlphaGo had 2 stages. In the first stage, it learned by imitating human expert players, but the problem here is that it couldn’t surpass the level of the very best human players. The way this was done in the second stage, was by just playing lots and lots of games based on a simple reward function of winning to improve itself.
What is this step 2 look like in the domain of language? The issue is that there isn’t a clear reward criteria we can judge on.
LLM OS
LLMs as the fundamental part of a future OS. CPU = LLM, Ram = Context Window, Disk = Embeddings + File System, I/O = video + audio
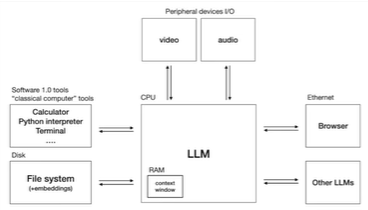
Things an LLM might be able to do in a few years:
- Read and generate text
- Browse the internet
- Use existing software infrastructure
- See and generate images and video
- Hear, speak, generate music
- Think for long periods of time using a System 2
- Self-improve
- Customization and finetuning, “app stores”
- Communication with other LLMs
Security Concerns
Jailbreaks
- You can convince the model using various prompt engineering tactics.
- Base-64 encodings (general translation issues because the finetuning will be mainly in English)
- Universal Transferable Suffix: optimizing words to find a specific suffix to any prompt that can jailbreak the model
Prompt Injections
- Using new mediums to create attacks
- Universal Transferable Suffix but for images
- Prompt injections hidden in web pages for an LLM that uses RAG on the internet
- “Sleeper agent” attacks: poison the data with a trigger word that will cause the model to behave undesirably when introduced